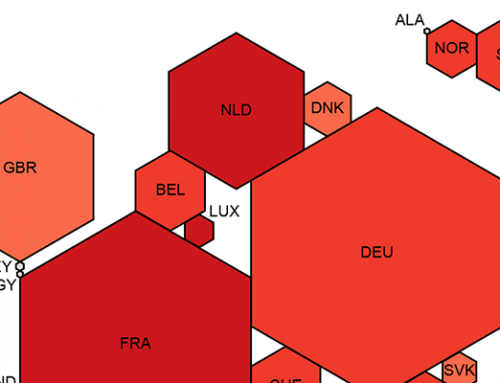
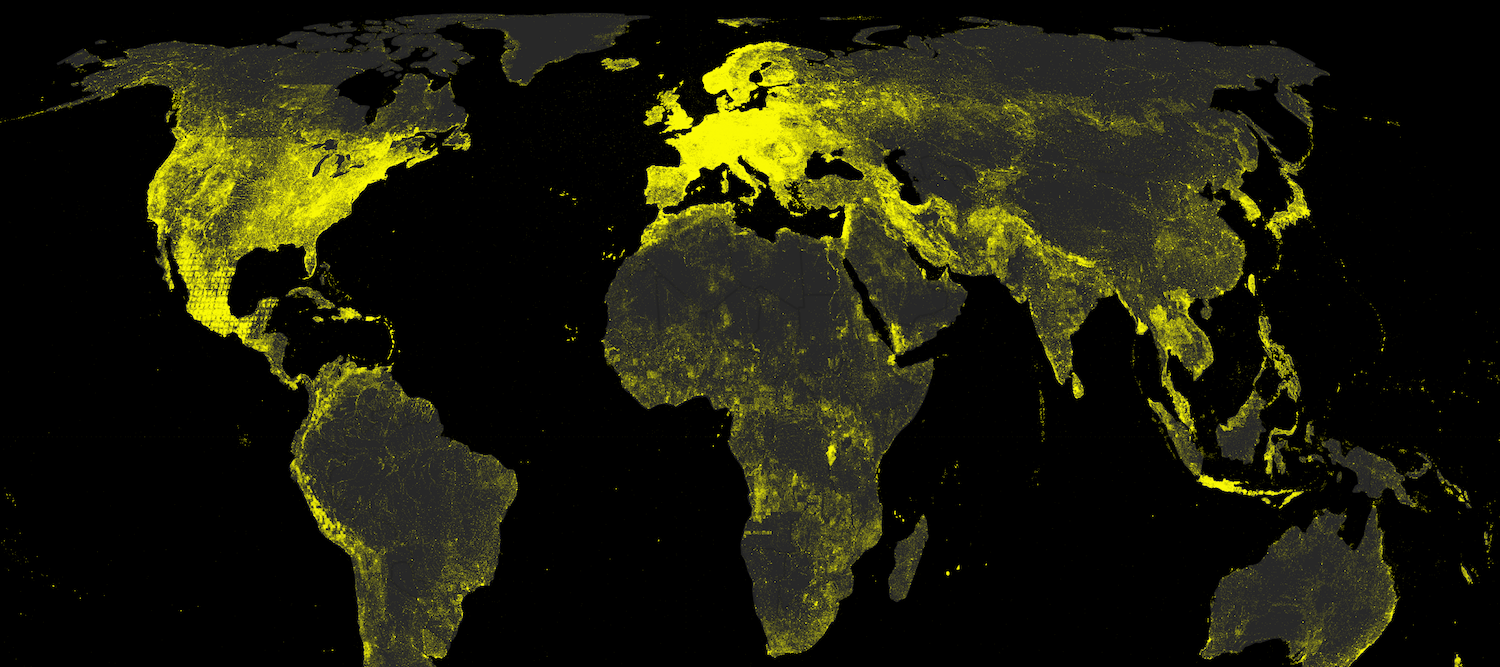
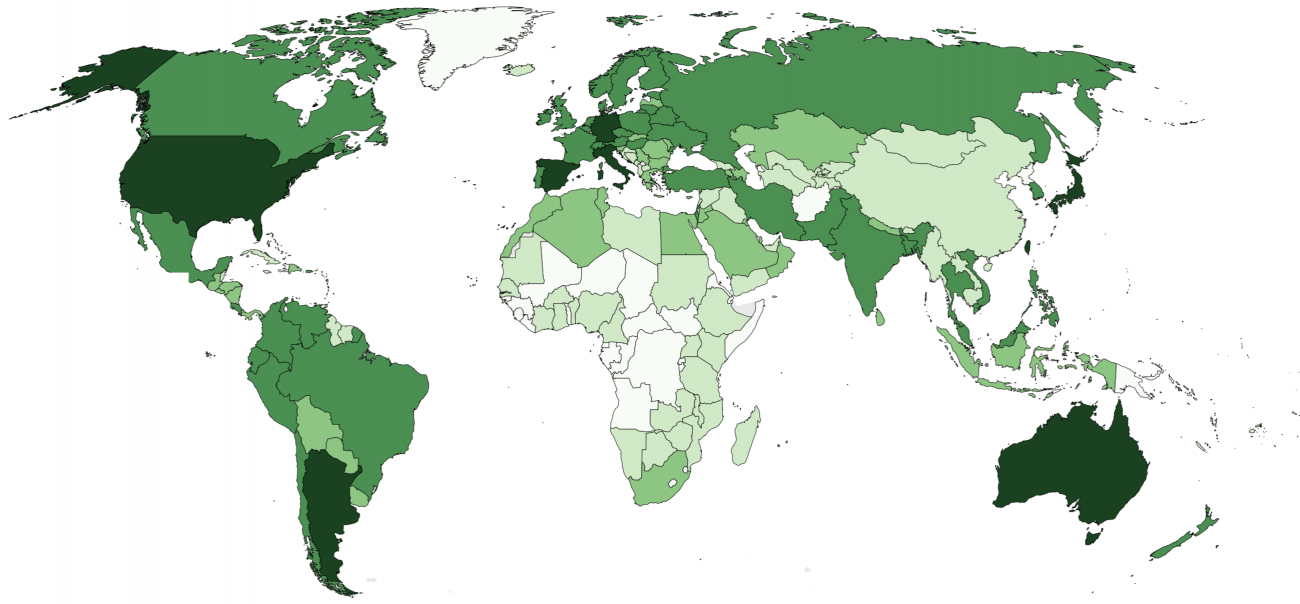
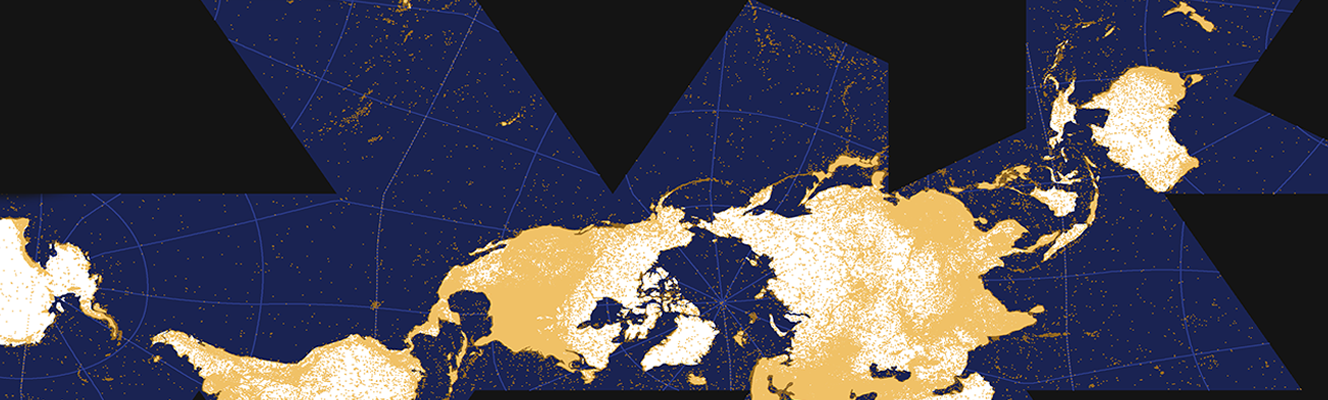
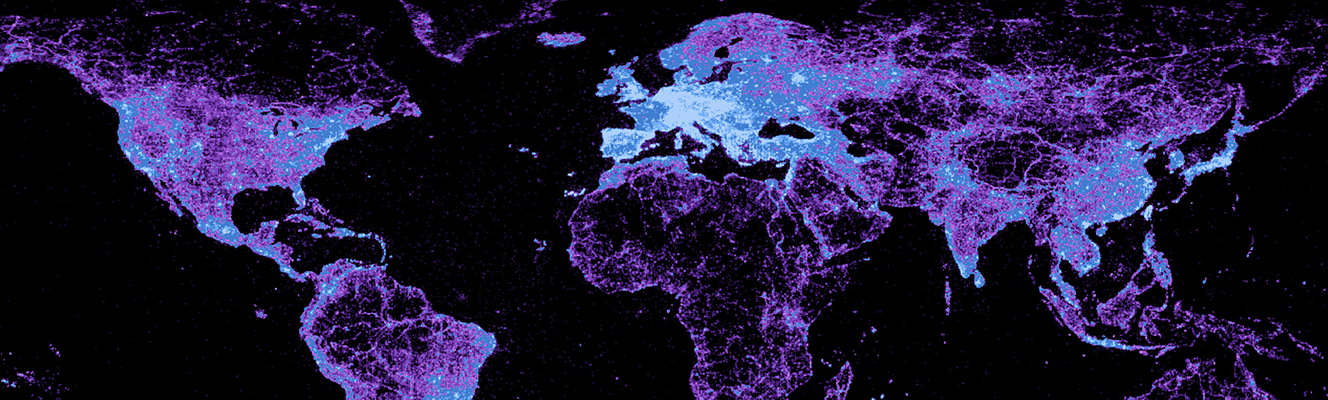
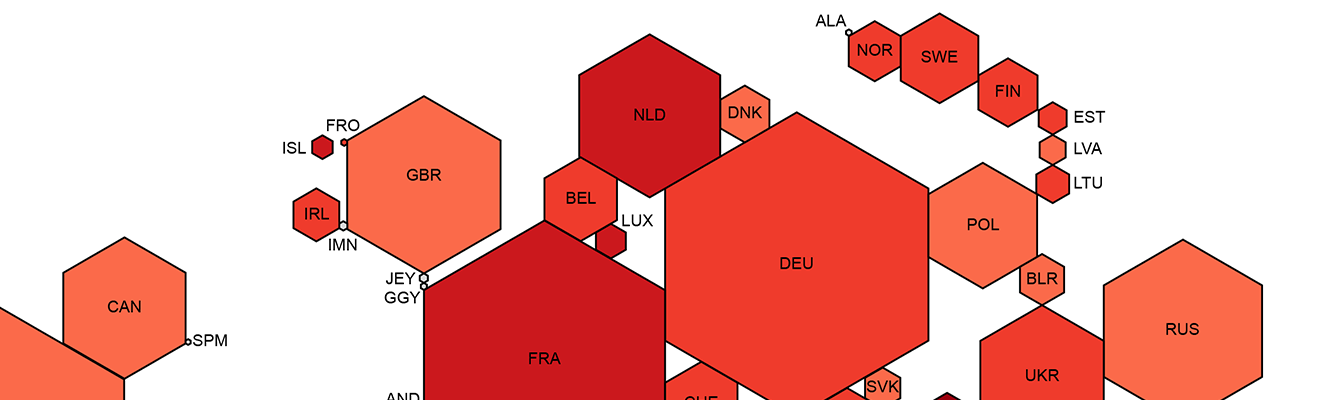
The World as Seen by a Search Algorithm By |2018-03-28T16:32:04+01:00March 28th, 2018| Related Posts Wikipedia’s Global Geography Gallery Wikipedia’s Global Geography The Uneven Geography of Wikipedia Gallery The Uneven Geography of Wikipedia Geographically Uneven Coverage of Wikipedia Gallery Geographically Uneven Coverage of Wikipedia A World’s Panorama Gallery A World’s Panorama The anonymous Internet Gallery The anonymous Internet
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}