(Click to see full image)
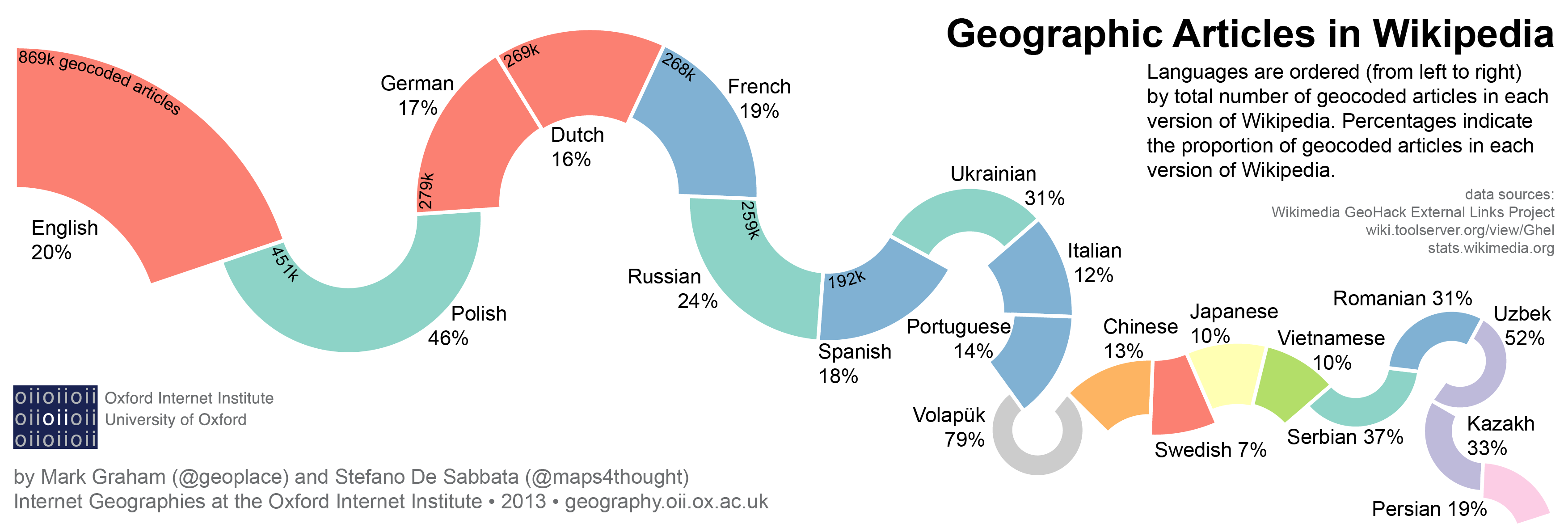
This graph illustrate the percentage of geo-referenced articles in the twenty editions of Wikipedia containing the largest number of geo-referenced articles.
Data
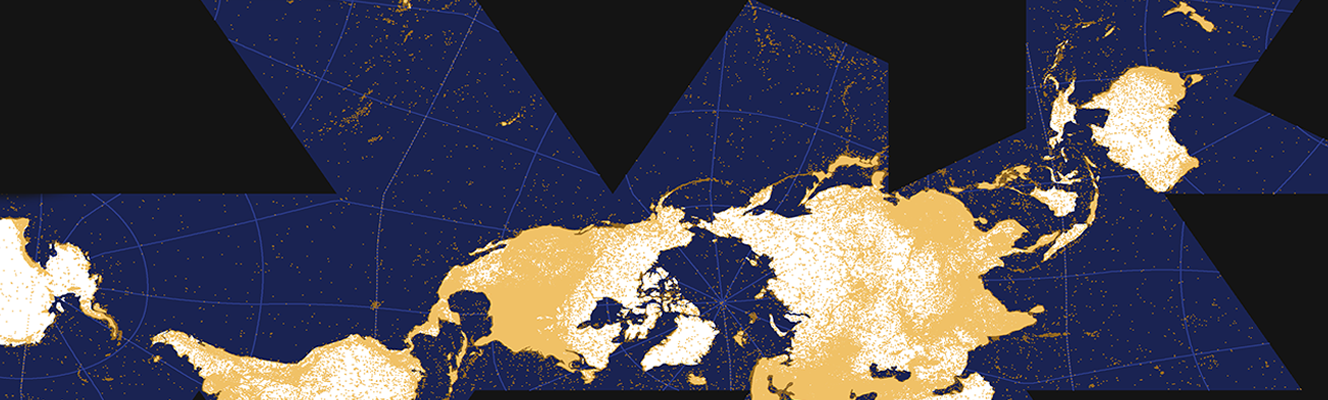
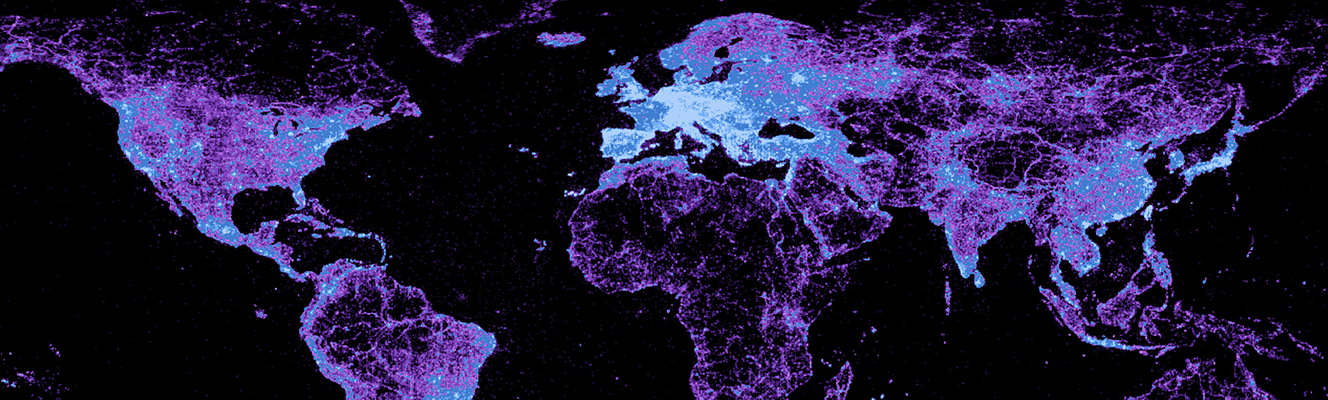
The Terra Incognita project by Tracemedia investigates how Wikipedia has evolved over the last decade, mapping geographic articles, and date of creation, for over 50 languages. The maps highlight geolinguistic biases, unexpected areas of focus, and overlaps between the spatial coverage of different languages.
The project was developed using geo-coded Wikipedia articles from the Wikimedia Toolserver Ghel project (Geohack External Links), and article metrics that were collated using Toolserver scripts. The Ghel data dumps date to July 2013.
Only articles with primary coordinates are used, that is “where the location should be considered the primary object(s) in the page […]. Generally this should be one per article, but may be more with current corner cases with source and outlet of lakes and rivers” (Ghel project).
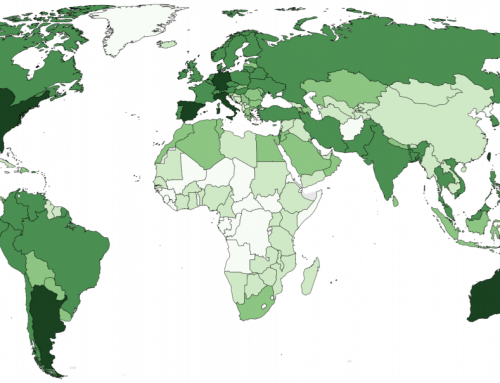
As illustrated in the featured graphic above (see table, bar chart by the Terra Incognita project), the percentages of geocoded articles in Wikipedia editions vary largely, from a minimum of 2% (Hindi Wikipedia) to a maximum of 46% (Polish Wikipedia), with the exception of the constructed language Volapük, whose Wikipedia edition includes a 79% of geocoded articles. Most large editions in Germanic and Italic languages contain between 12% (Italian Wikipedia) and 20% (English Wikipedia) of geo-coded articles.
Findings
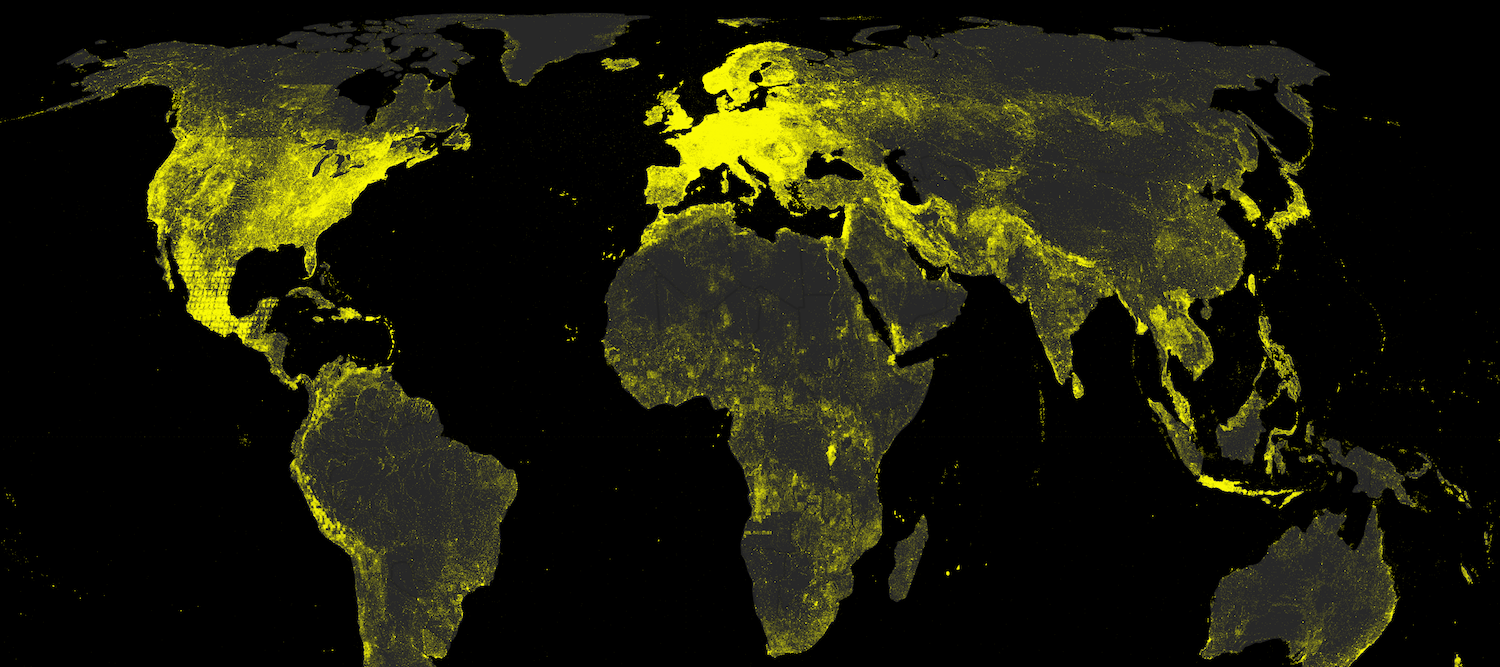
The primary goal of the illustrations presented in this piece is to visualise how Wikipedia has very divergent geographic coverage in different languages. The tool also allows us to look at the date at which every one of the 4.5 million geocoded articles in Wikipedia was created: thus enabling us to see how the focus of different linguistic communities has evolved.
Most geo-coded Wikipedia articles are located in the countries where the language is listed as an official one.
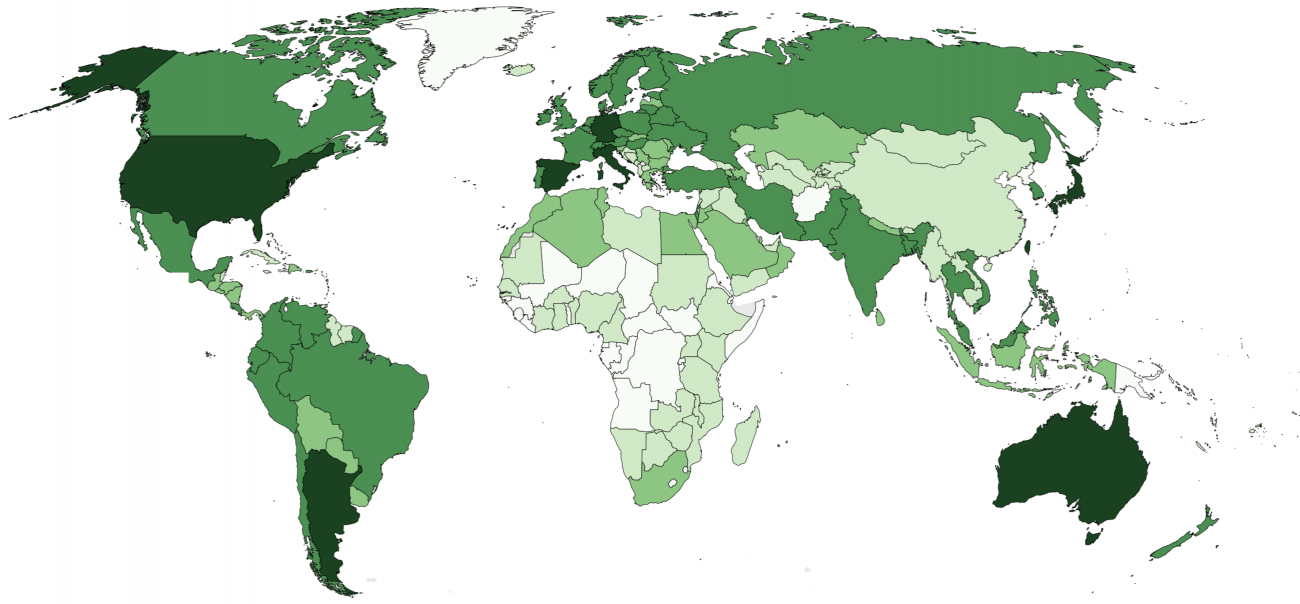
One of the most interesting patterns that we can see in the data is that over 70% of articles written in that languages are spoken predominantly in a single country (e.g. Czech or Italian) only exist in that language. This means, for instance, that there might be articles about thousands of Czech villages written in Czech, but not English, French, German, or even Japanese.
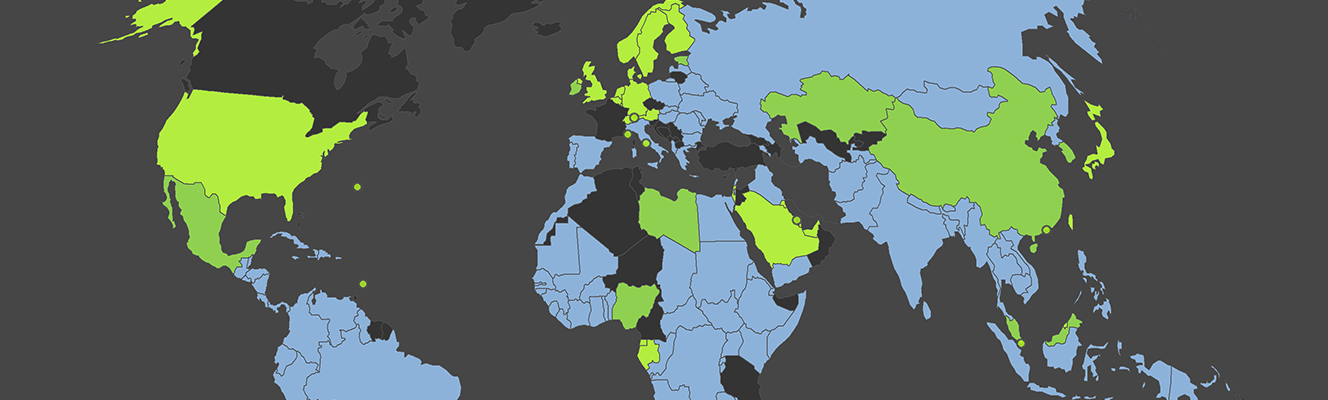
Furthermore, Terra Incognita studies how two or more languages intersect with each other, when two distinct Wikipedia editions refer to the same location, in which is the proportion of such articles in the collections. These linking points can be visualized by means of language intersection maps, which highlight location referred to be more than one language.
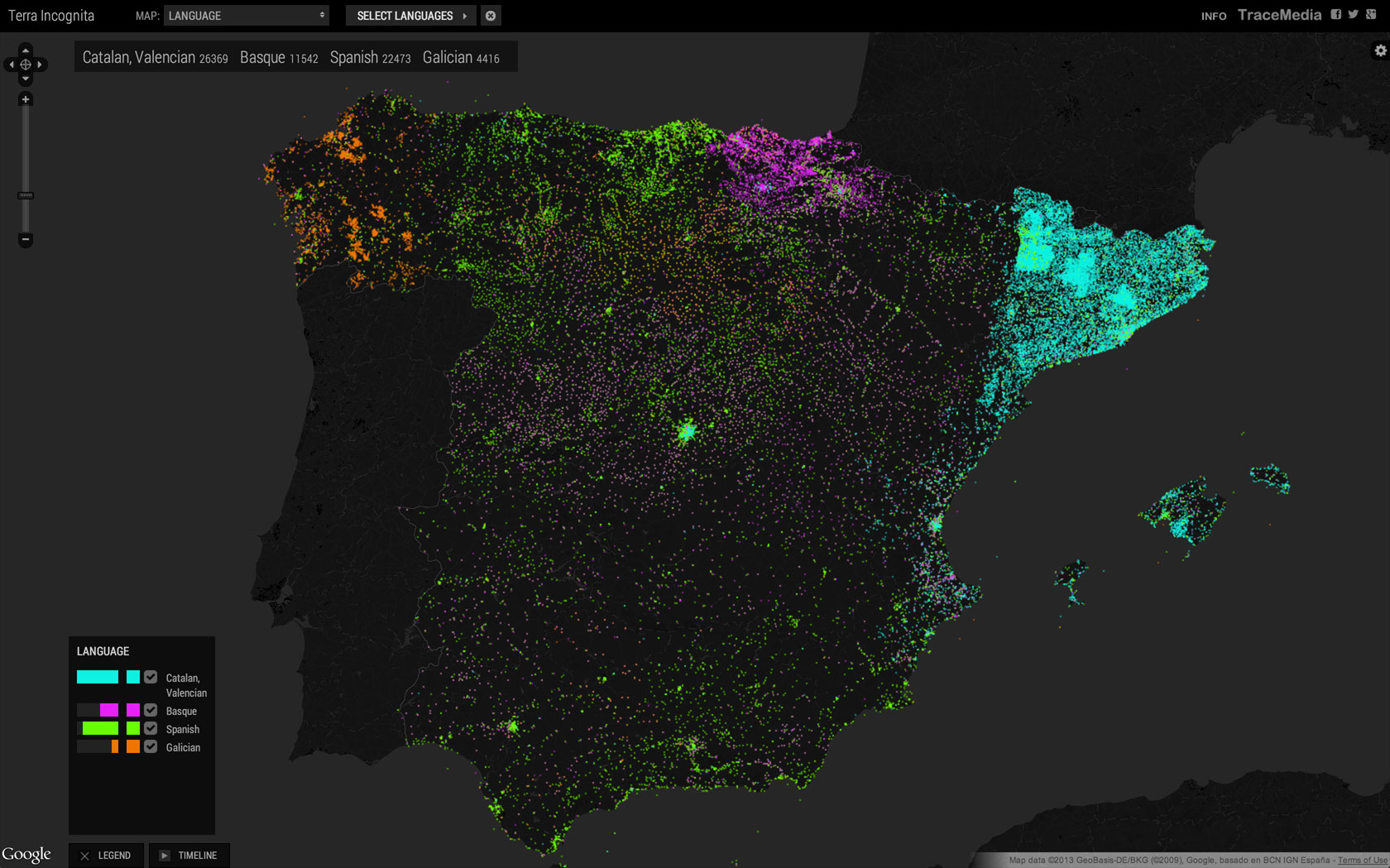
Some of the most interesting linguistic comparisons can be seen when comparing the geography of different languages in multilingual parts of the world, such as Spain. We can see a high density of articles in Galicia, the Basque Country, Catalonia and to a lesser extent Valencia in their respective languages. Spanish (Castilian) is more evenly represented across the whole country.

A similar approach can be taken to explore the distribution of Wikipedia articles in some of the main languages spoken in South Asia. The map here, for instance, includes Bishnupriya Manipuri, Hindi, Nepal Bhasa and Tamil.
Regional variations are not as strongly pronounced as they were in the Spanish case (Tamil, which is concentrated in South India and Sri Lanka is a notable exception). The overlap of the languages with each other is consistently between 12% and 16% with the exception of Bishnupriya Manipuri and Nepal Bhasa where the majority (65.1%) of articles are shared. These shared articles are distributed across India, and the distinct articles are in the native Nepal and Bangladesh.
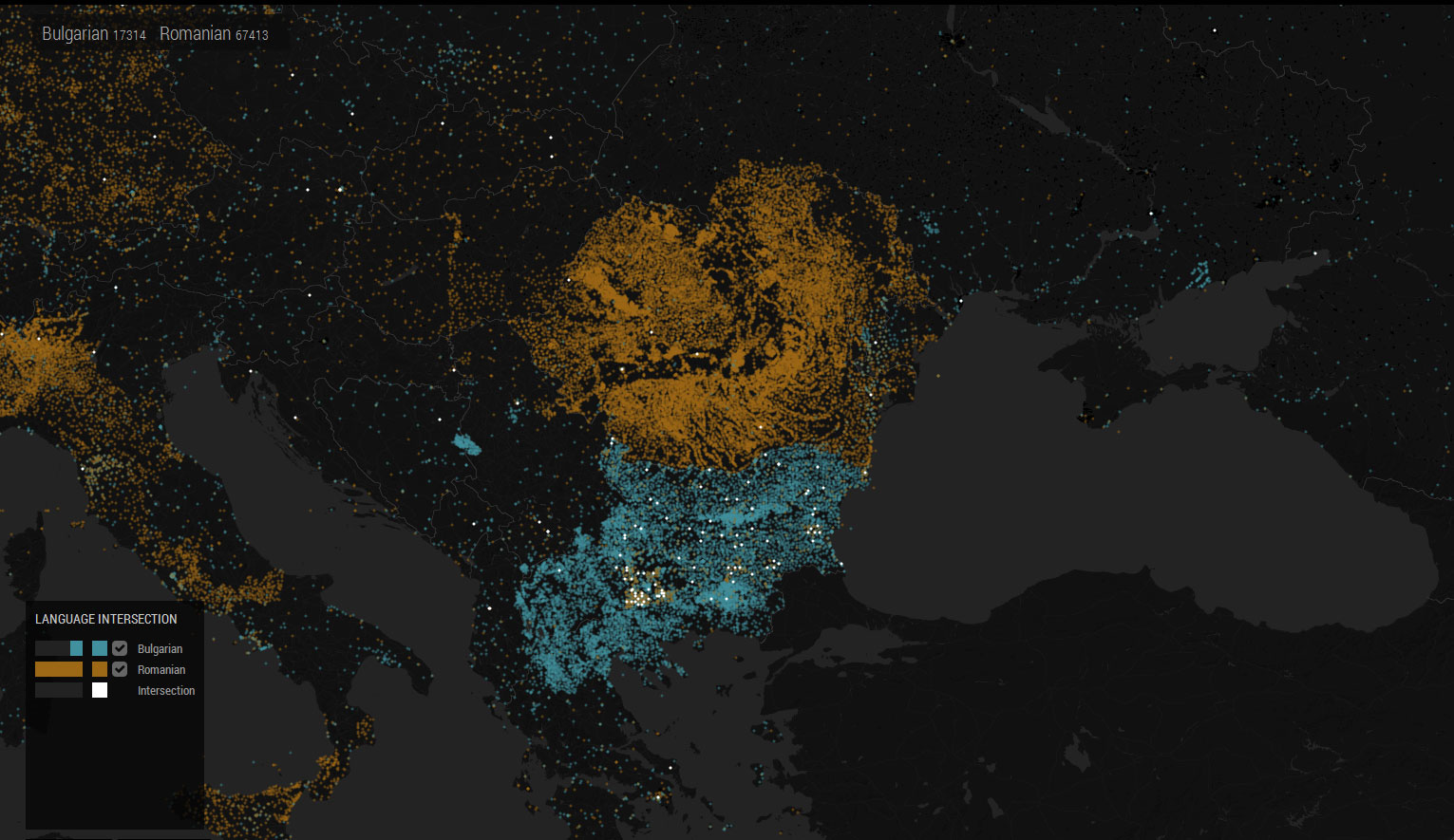
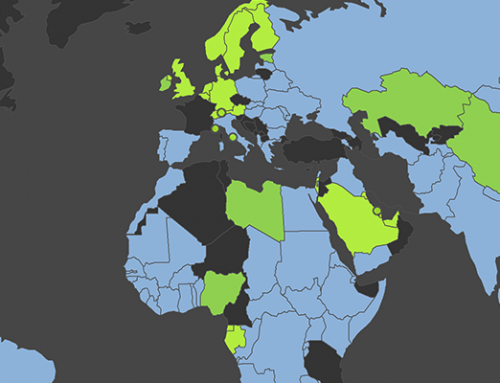
Romanian and Bulgarian Wikipedia articles are largely concentrated within the political boundaries of their respective countries. There is very limited overlapping of geographic content except in major cities.
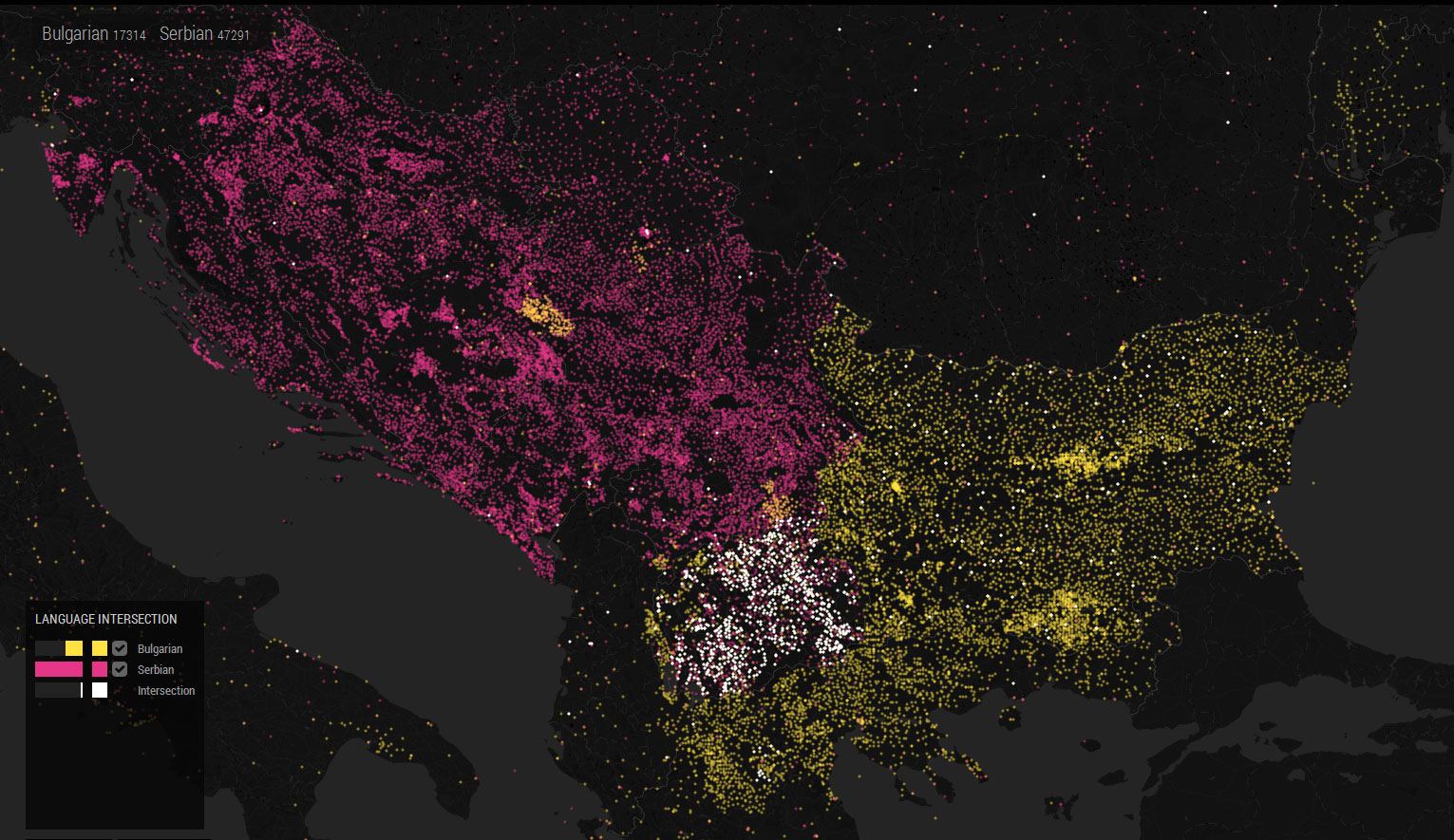
Bulgaria and Serbia also share a border and are both Slavic languages (in contrast to Romanian, which is a Romance language). There is a much higher percentage of language intersections for articles between Bulgarian and Serbian than between Bulgarian and Romanian. For instance, a large number of intersected articles appear in Macedonia, which shares a border with Serbia and Bulgaria.
These maps, and the associated Terra Incognita tool, offer us an insight into not just patterns in Wikipedia, but also the geographic spheres of interest to different linguistic communities. As we work to better understand online geographies of knowledge, these maps allow us to ask important questions about who is representing and being represented by who.
Credits
The project was created by Gavin Baily and Sarah Bagshaw at TraceMedia, and was supported by funding from the Arts Council of England Grants for Arts and the National Lottery.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}