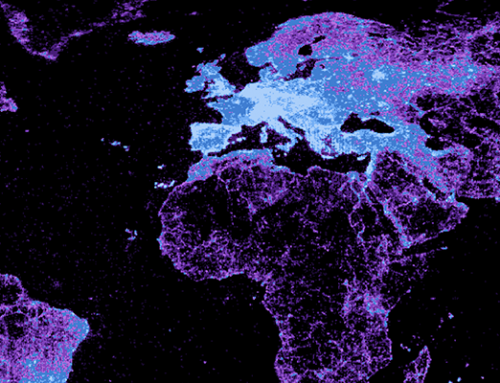
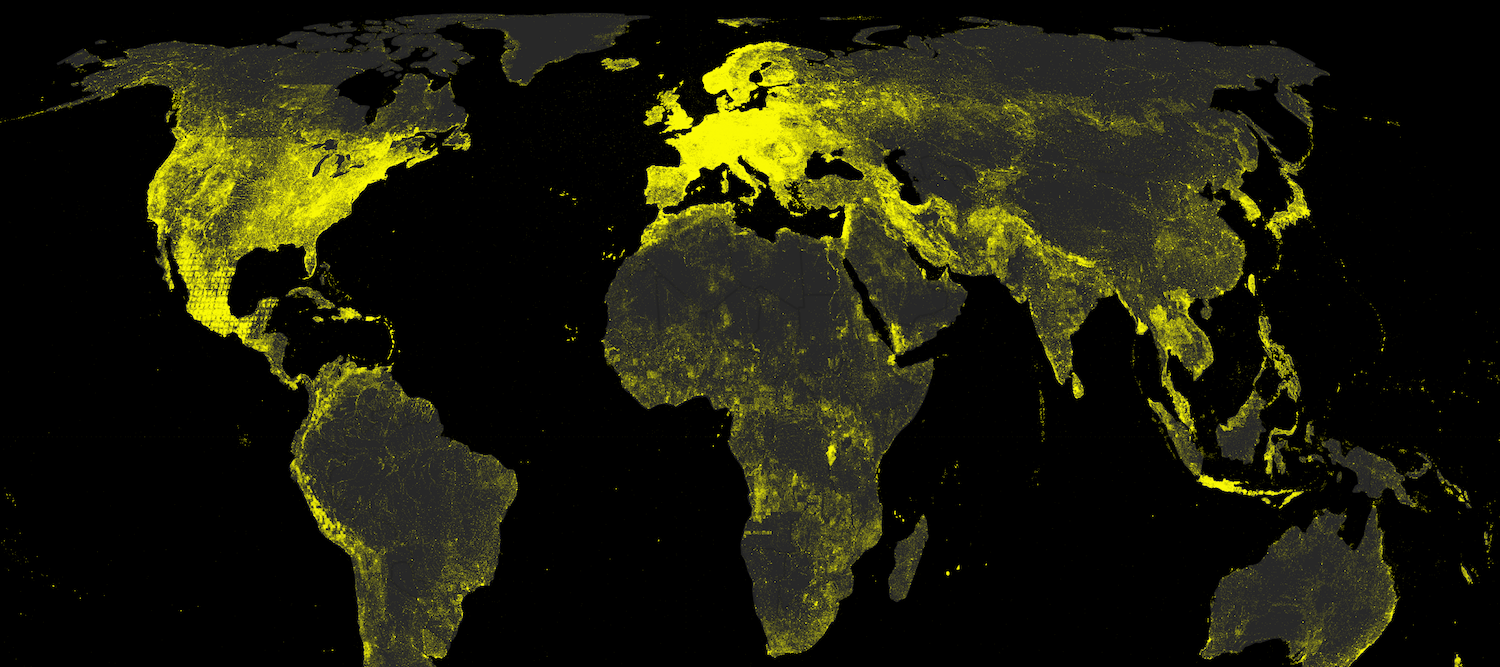
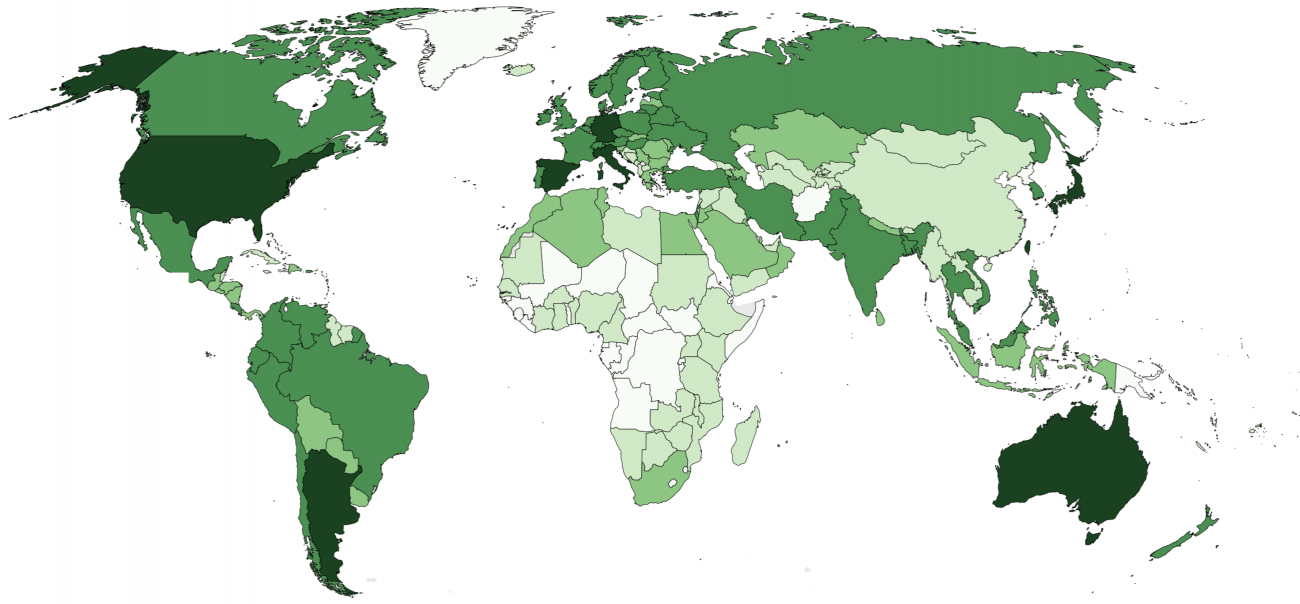
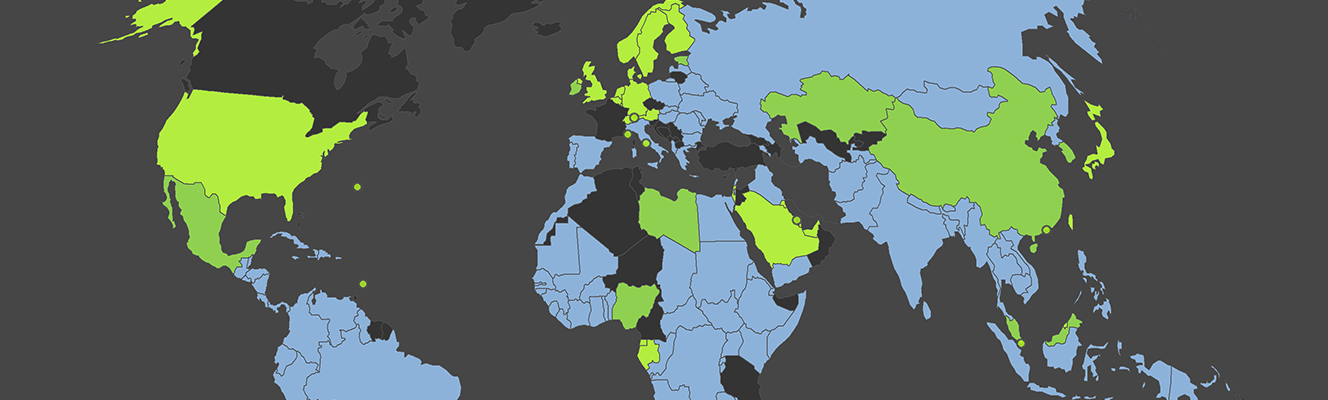
Mapping the GeoNames Gazetteer By |2018-03-20T12:18:56+00:00June 20th, 2013| Related Posts Wikipedia’s Global Geography Gallery Wikipedia’s Global Geography The Uneven Geography of Wikipedia Gallery The Uneven Geography of Wikipedia The World as Seen by a Search Algorithm Gallery The World as Seen by a Search Algorithm Geographically Uneven Coverage of Wikipedia Gallery Geographically Uneven Coverage of Wikipedia A World’s Panorama Gallery A World’s Panorama
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}